
-

Facebook CEO Mark Zuckerberg
-

Amazon in Silicon Valley, San Francisco bay area
IT&デジタル業界最新業界
IT&Digital Industry Latest Information
チャットGPT「仕事」の再定義必須に 生成AIが変える社会 2023/05/08
ポイント
○身体感覚も知性獲得の重要な要素になる
○定型的な業務はほぼAIに置き換え可能
○内部データとの連動で格段の能力向上に
人工知能(AI)が職を奪う話は繰り返し現れる。2013年、英オックスフォード大学のカール・フレイ氏とマイケル・オズボーン氏が、米国では労働人口にして4割以上の仕事が機械すなわちAIに取って代わられるという予想を発表し、衝撃を与えた。
すでに起きた、AIが人間の仕事を奪った事例がある。米金融大手ゴールドマン・サックスのニューヨーク本社では、00年のピーク時に600人いたトレーダーが17年に2人になった。そのかなりの人数がヘッジファンドに流れたそうだが、そこでも大きな貢献はできていないという。
一方、データを用いた市場の数学的分析やトレーダー用のソフト開発といった新たな分野で、多くの人が雇用されている。AIはもちろんのこと、技術やビジネスの変化に応じて、消える仕事、出現する仕事は変わるものだ。
さて、目下話題になっている、チャットGPTなどのテキストを対象にした生成AIが、人間の仕事を奪うかという問題について考えてみたい。
生成AIは、人間のように文書を理解しているわけではない。まず、極めて膨大な言語データから、ある単語や言い回しの間の関係を捉えることができる「トランスフォーマー」と呼ばれる深層学習の手法を駆使して大規模言語モデルをつくる。これを用いて、質問に対して関連する文書を組み合わせ、適切な回答を生成している。
いくら言語データが膨大でも、書かれていないことを質問されることもある。大規模言語モデルは多少なりと関連した文を多数探し出してきて切り貼りし、つじつまが合うような回答をつくれる。ただしこれは関連性による処理なので、昨今問題視されている的外れな回答や、間違いも多い。
使っている言語データが大きくなるほど間違いは減り、質の良い回答を出すと期待される。この考え方は10年以上前から知られていたが、計算機の速度向上で、大規模言語モデルのパラメーター(最適化の程度を決める設定)が初期の1億2500万から1750億に拡大したことで、チャットGPTのような性能が出せるようになった。
生成AIは強力だが、このまま言語データを大きくし、パラメーターの数を増やすだけで状況や文脈を全てカバーできるかは疑問が残る。あくまで関連性を用いているので、許容できないレベルの回答もしばしば目にする。仕事で使う場合には、その正否を判定できる人間がチェックする必要がある。
チェックには、正確な知識、かつ仕事の目的を状況に応じて正しく解釈する柔軟性が必須だ。漫然とルーチンワークをしていたような人は、一見知的な仕事をしていたように見えても、このようなチェックはできず、仕事を奪われる。
また、良い回答を得るには良い質問が必須なので、質問を洗練させるプロセスを支援する手順が要る。そのために、別種の生成AIが投入されるかもしれない。ただ質問洗練のためのAIは個人に適応化したものにならざるをえず、まだ技術進歩が必要である。
さらに、人間の知能や知性は脳の中だけにあるのではない、という考え方は広く受け入れられている。
知性とは、脳以外の身体感覚が総合して生まれるものである。例えば、ふわふわした縫いぐるみは触覚と視覚から人間の感情に影響を与え、その感情が言語として表現される。縫いぐるみの中にロボットを仕込むPAROという装置は、米国ではすでに医療用機器として使われている。
このような身体性に基づく知性や感情は、言語データを増やし、言語モデルを大きくするだけで獲得できるとは思えない。もちろん、痛みなどの身体感覚を表現する言語データもある。しかし、これを生成AIを使う人間の身体状態と結びつける作業は、やはり人間自身が触覚などを介して行わなければならない。
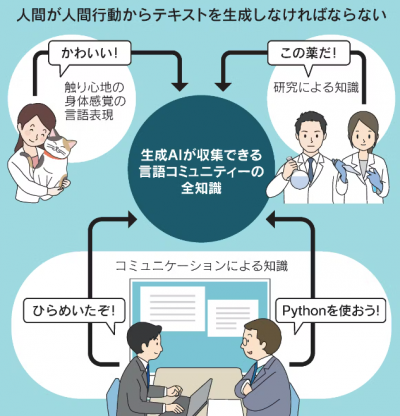
身体性のほか、他人とのコミュニケーションや対話の中に知性が存在するという考え方もある。
例えば、話し手と聞き手の上下関係、お互いの状況などを考慮した言語表現は、対話を継続するために使われる。しかし生成AIが対象にしているのは、話し手と聞き手の関係に依存する言語表現ではなく、表現された意味内容、すなわち知識にとどまる。
また、個人の持つ知識は不完全であり、さほど大きいものではない。一方、英語話者のような巨大な言語コミュニティーが持っている知識は非常に大きく、完全さも高い。生成AIはインターネット上から膨大な言語データを収集し、それを学習することによって、このような巨大コミュニティー並みの知識を獲得しているのだ。
生成AIを辞典や相談相手として使うと、自分の知らなかった知識に基づく「正しい」回答が得られる。まるでその分野の専門家に質問しているようで、これは使えるという感覚を多くの人が持つようになったのが実際のところだろう。
ならば、インターネット上のデータの不完全さをどう補えばいいのだろうか。まず、日々のニュース記事などを即時的に取り入れて学習していけば、現在の社会状況に即応した回答をつくることはできそうだ。
さらに、インターネットに接続されていない、もしくは制限されている企業や自治体など組織内部の非公開データはどうか。この実用的で膨大なデータを用いることができれば、専門的な分野の知識は飛躍的に高まるだろう。
具体的には、セキュリティーに配慮して、企業内文書専用の小型の社内生成AIを企業内に置き、それと公開生成AIの提供するAPI(アプリケーション・プログラミング・インターフェース)とを組み合わせて回答を得るような、ハイブリッド生成AIをつくることが考えられる。
例えば、社内生成AIが不十分な回答しか出せないときは、問題点を公開生成AIに質問をし、その答えを社内生成AIに与えて回答を洗練することを繰り返す方法などが考えられる。技術的にはまだ不確定だが、可能性はある。
そしてこのような社内生成AIと公開生成AIを接続したハイブリッド型の生成AIができれば、総務、経理、営業、製造に至るまで、企業内の文書処理はほとんど自動化できる。現在、企業活動の大きな部分を占めている文書処理の仕事は、ごく少数の従業員で行えるだろう。
よって、新たに記述すべき新規なアイデアを出せる人以外は、不要になるかもしれない。これは、最初に述べたゴールドマンが600人のトレーダーを2人に減らしたのと同じことが種々の企業で起きる可能性を示唆する。
企業など組織において、定型以外の仕事とは何かを模索する時代に入ることを予感させる。この段階でAIをどう使うのか、倫理的な問題を含め、まだまだ手探りの状態である。
(日本経済新聞)